Reverse-Engineering Belgium: De Lijn
2015, An exiting time to live in. It’s only recently that Belgium is pushing for open data for the government, an “Open Government” if you will.
At first I wanted to reverse-engineer the “De Lijn” mobile API, however it recently came to my attention that they are seemingly investing in a newer, more modern web API instead, one that shows a lot of promise.
Why is it more modern? It uses JSON, which is a big deal. They used to use SOAP as the protocol to transfer data from the server to a mobile device, but it looks like they want to migrate away from that, and with good reason.
Reasons that I won’t go into here, you’ll find many rants / articles all over the internet.
However, having 2 active APIs (REST + SOAP) will most likely put them — from a developer’s perspective — in a bit of an awkward situation since they now have to maintain two APIs.
So sit back, grab some coffee and let’s take a look!
First look
The first thing we will want to do is try and capture the API endpoint, a straight-forward task.
Upon opening the website I can clearly see an XMLHttpRequest (XHR) going to their server, which is coming from an AJAX request from somewhere inside their JavaScript codebase.
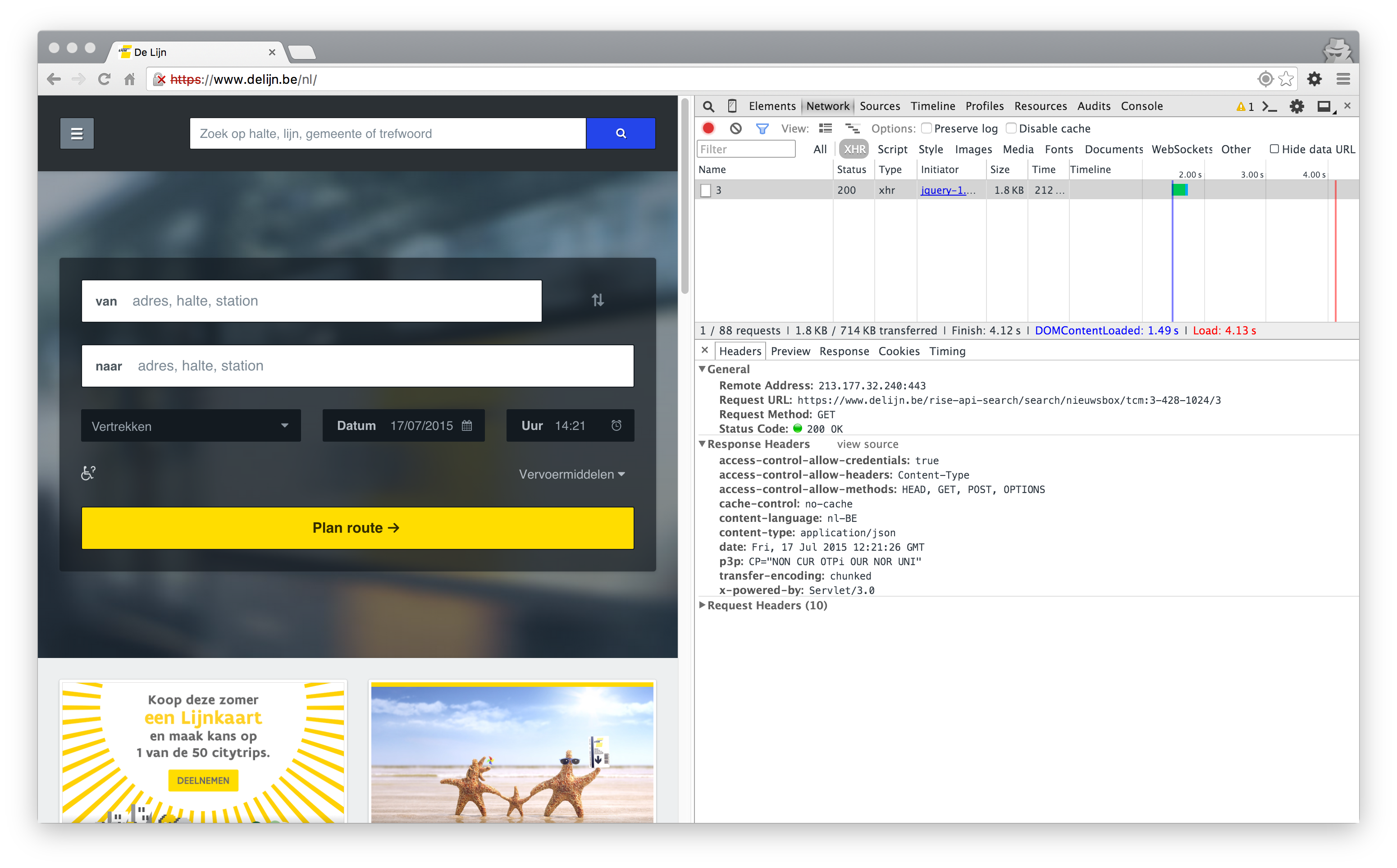
We can immediately spot one of the API endpoints that are used for their new API:
https://www.delijn.be/rise-api-search/
However, there is a second — more interesting — API endpoint which you can find when using their route planner.
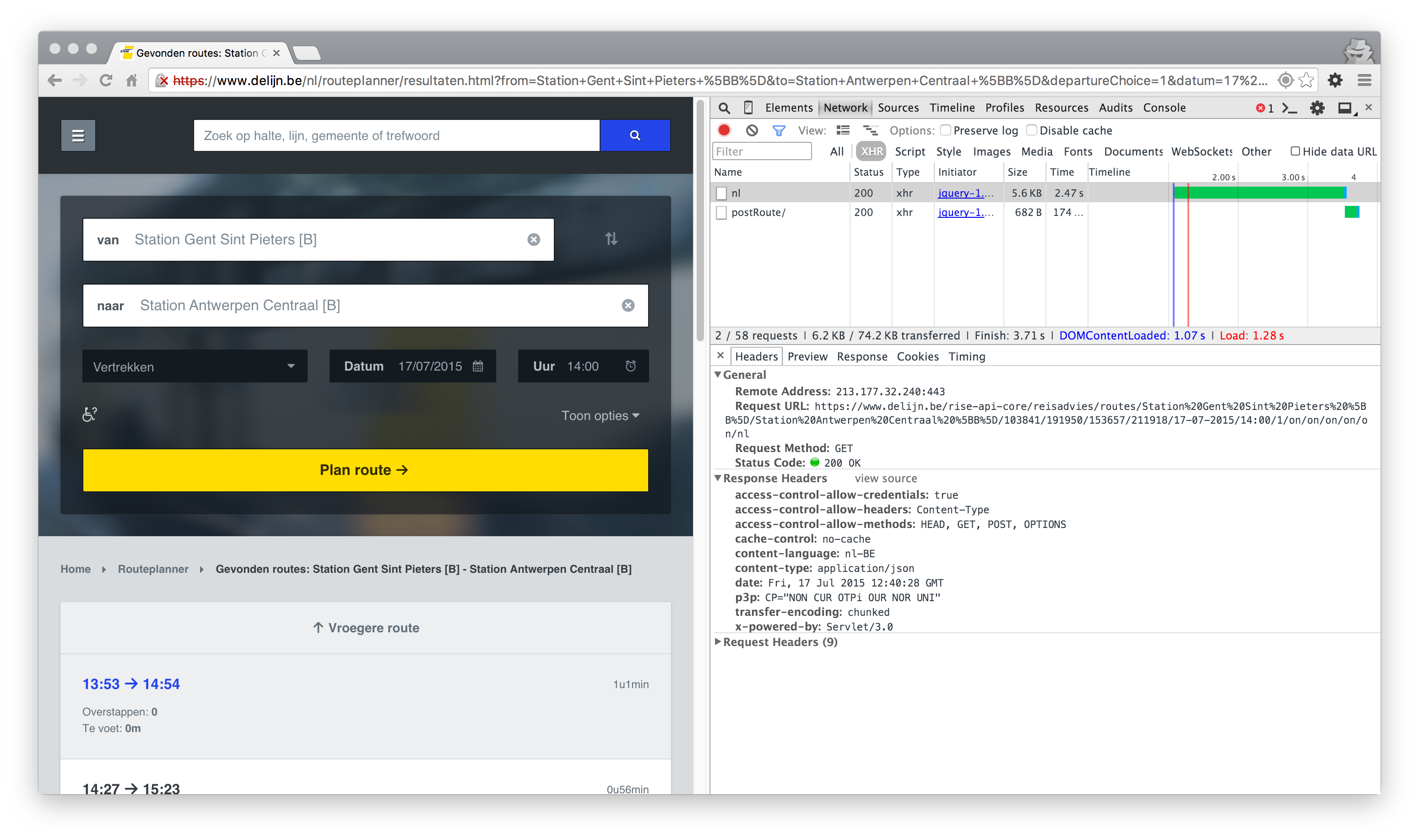
https://www.delijn.be/rise-api-core/
A few positive observations can be made:
- They use SSL for their API communication. I would not have expected any less, SSL/TLS should always be used to ensure you protect the data of your users.
- In contrast to RailTime, they DO know how to build RESTful urls.
And a few minor annoyances can also be found:
- They always return
content-language: nl-BEeven though I requested the content in English. Weird, it must be hard-coded in the server response.
- It’s
x-powered-by: Servlet/3.0, which means they have a Java backend. I had my hopes up for a more… modern approach, however I’m not complaining as long as it gets the job done. Do note that it’s considered “bad practice” to expose any information about your backend to the user for security reasons. It’s easier for malicious users to attack your servers if they know which software it’s running and thus which security exploits to use. - They return a
p3pheader.
Whoa! That’s something I haven’t seen in.. forever! P3P was designed back in the day for privacy purposes so they could declare their intended use of information they collect about web browser users.
However, Internet Explorer 6 was the only browser that actually implemented this. Firefox used to implement this spec for a while, however they removed all code related to p3p back in 2007.
Both Facebook and Google have stated they they don’t support this spec at all, so maybe we shouldn’t either? It’s all just useless header overhead at this point.
W3 spec for more information: http://www.w3.org/TR/P3P11/
And one last mysterious observation when retrieving the latest news articles:
https://www.delijn.be/rise-api-search/search/nieuwsbox/tcm:3-428-1024/3
What is that mysterious tcm value? Honestly, I’ve never seen anything like it before and removing the tcm parameter will yield a 404 Not found.
Upon further inspection, the tcm value appears to be the “news category”, which I could extract from their source-code.
function loadNieuwboxGroot() {
if(nieuwsCategoryGrotebox) {
$.ajax({
url : apiUrl + "/search/nieuwsbox/" + nieuwsCategoryGrotebox + "/" + publicationId,
type : "GET"
})
}
And the value is actually inserted into the index page as such:
<script type="text/javascript">
var nieuwsCategoryGrotebox = 'tcm:3-428-1024';
</script>
<script type="text/javascript">
var publicationId = '3';
var isUserLoggedOn = false;
var taalString = "nl";
</script>
And changes depending on the language you selected on the website.
It’s odd to see an API that’s tightly coupled to the client (the web browser), not to mention the variables that are just floating on the main window object.
EDIT: Someone pointed out to me that “tcm” most likely stands for “Tridion Content Management”, the CMS that De Lijn uses to publish their articles.
Authentication
Let’s take a look at how user authentication is implemented.
To be able to log in we’ll have to use a method that is not exposed in the API (yet?) so we have to post to a different url endpoint, the naming (and the server response) of the request makes me believe that they use auth4u, an authentication framework developed by a Belgian company.
The request is straightforward, note that we’re posting and it’s a url encoded form.
POST /auth4u/rememberme HTTP/1.1
Content-Type: application/x-www-form-urlencoded
Host: www.delijn.be
Content-Length: 90
username=foo%40bar.com&password=foobar123&referer=%2Fnl&rememberme=true
The response from the server however is what we actually want to see.
HTTP/1.1 302 Moved Temporarily
content-length: 1408
content-type: text/html
location: https://www.delijn.be/nl
Set-Cookie: rememberMeToken=4ddb2402-a345-4e73-897d-65d4d9a1042e; Path=/; Expires=Fri, 27-Apr-35 14:37:59 GMT
Set-Cookie: JSESSIONID=0000o2v7SFvpq8n_ibLEMfjQJ8Q:17nsfk695; Path=/auth4u
Set-Cookie: PD-S-SESSION-ID=1_2_1_Idl8IIpQWqtAgaXrjac-jf0xFiQwVRWl1qXnUpY89WJOKYJ7; Path=/; Secure
This tells a few things:
- They are using cookies for storage
- It’s using session-based authentication
- The cookies are not HttpOnly
- The cookies do not have the SecureFlag, which leads to an increase of possible attack vectors
I’ll go into some more detail here
They are using cookies for storage
Typically, cookies are not used for authenticating a user when talking over an API because it tightly binds a client to a web browser, cookies unfortunately are not available when — for example — you’re working on embedded devices in an IoT environment, these small devices simple don’t want all the overhead that is shipped along with a web browser. So no cookies on your RaspberryPi. (Get it?)
However, when you decide to use session-based authentication, then cookies are the most practical solution, more about that later.
Regarding web apps, a more commonly used storage mechanism for authentication is either LocalStorage or SessionsStorage which can easily be accessed through JavaScript.
On embedded devices however, you can store them anywhere you want, either somewhere in a persistent storage or in memory.It’s using session-based authentication
If you have an API that you want to expose to users or developers, you need to be sure that it’s scalable and fast. Session-based authentication however is slow and scales very poorly, unless you have a big architecture to cope with that particular issue. I’m a start-up minded guy with a good sense of cost-efficiency so sessions aren’t in my book.
A more scalable solution would be to use the more modern Token Based authentication. I suggest you read up on it a bit, it’s relatively new and brings a lot of good stuff to the table!
If you want you can read a good article on Sessions vs. Tokens by my friends over at Auth0: https://auth0.com/blog/2014/01/07/angularjs-authentication-with-cookies-vs-token/The cookies are not HttpOnly
This means that you cookies can be stolen using XSS or MITM attacks!
Simply put, HttpOnly is a flag that you can set on a cookie so that they are only sent as part of the header and disallows scripts such as JavaScript and even Flash from reading/modifying your cookies, which is a big deal.
The one piece of data that determines whether you are logged in as yourself or some one else is the session identifier in your cookie. If you can steal another person’s identifier then you can simply access their account and wreak havoc.
XSS and MITM attacks can be used to steal someone’s session identifier and gain access to their account. There are of course countermeasures to mitigate such attacks but I won’t go into that in here since it’s outside of the scope of article.The cookies do not have the SecureFlag
The SecureFlag, is — just like HttpOnly — a flag that you can set on a cookie. Simply put, this will force the browser to only send the cookie over TLS/HTTPS which is always encrypted.
This is part of mitigating the MITM attacks.
To authenticate requests tot the API, simply send over the session id cookies to the server along with the API request, although it’s fair to say that most API requests don’t require any sort of authentication anyway.
Some remarks
As always, I have some general remarks regarding the API as it currently stands. I’ll outline them here as best as possible.
Coordinates
They seem to use x/y coordinates for all their geo-based information so they have an API route that converts proper lat/long coordinates into their equivalent x/y coordinates.
Use the following route to convert lat/long to x/y: https://www.delijn.be/rise-api-core/locations/convert/{{lat}}/{{long}}
where {{lat}} is your latitude and {{long}} is your longitude.
Which will give you the x/y coordinate in a response similar to:
{
"halteNummer": null,
"idString": null,
"laatstgebruikt": null,
"locationId": null,
"markedString": null,
"xCoordinaat": 103853,
"yCoordinaat": 191981
}
In my opinion, they should just stick to using the familiar lat/long coordinates on the frontend and silently convert them to their x/y equivalents on the backend. That way the client doesn’t have to do an additional API request for the conversion and we can all work with data that we are most familiar with.
EDIT: A reader has notified me that these are most likely Belgian Lambert 72 coordinates.
API Gateway Pattern?
Interestingly, when I change a few parameters in the API requests I get a SOAP related error which leads me to believe that they’ve written an API gateway to do the actual conversion from SOAP to a more RESTful interface. I hope this is a trend that we’ll see more in the future, out with the ugly SOAP interfaces and in with the modern RESTful APIs!
Here’s the error in case you’re wondering:
Error 500: javax.xml.ws.soap.SOAPFaultException: An internal error occured in the Reisinfo service
This might also positively influence their maintainability, but regardless it’s always a pain to maintain multiple APIs instead of one.
In flux
During the writing of this article, they seemingly switched to different API endpoints. They used to have only a single endpoint (https://www.delijn.be/rise-api-web/).
They now have an endpoint for their “core” requests (https://www.delijn.be/rise-api-core/) and a separate endpoint for “search” related requests (https://www.delijn.be/rise-api-search/).
It’s possible that this is for performance reasons so they can load-balance their different requests, although they could have done it all the same without changing the old endpoint but this would have required a bit more configuration on their end.
Documentation
For me personally, documentation is on my number one list of important tasks when building a new API.
Therefore I’d like to document all the routes and available parameters that go with them, but I’m not going to do so in this post so I’ve created a blueprint that can be viewed on Apiary.
You can check out the source code here (MIT licence): https://github.com/MichielDeMey/delijn-api
Or view the generated documentation on Apiary: http://docs.delijn.apiary.io/
Feel free to contribute!
Thanks! I’d like to thank my brother, Gilles, for helping me out with the documentation.